消费分布规律的分类
为研究辽宁、浙江、河南、甘肃、青海5省份在某年城镇居民生活消费的分布规律,需要用调查资料对这5个省分类。数据见下表:
| 指标 省份 |
X1 X2 X3 X4 X5 X6 X7 X8 |
| 辽宁 浙江 河南 甘肃 青海 |
7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29 7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87 9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76 9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81 |
其中,X1:人均粮食支出; X2:人均副食品支出;
X3:人均烟、酒、茶支出; X4:人均其它副食品支出;
X5:人均衣着商品支出; X6:人均日用品支出;
X7:人均燃料支出; X8:人均非商品支出。
在科学研究、生产实践、社会生活中,经常会遇到分类的问题。例如,在考古学中,要将某些古生物化石进行科学的分类;在生物学中,要根据各生物体的综合特征进行分类;在经济学中,要考虑哪些经济指标反映的是同一种经济特征;在产品质量管理中,要根据各产品的某些重要指标而将其分为一等品,二等品等等。
这些问题可以用聚类分析方法来解决。
聚类分析的研究内容包括两个方面,一是对样品进行分类,称为Q型聚类法,使用的统计量是样品间的距离;二是对变量进行分类,称为R型聚类法,使用的统计量是变量间的相似系数。
设共有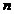 个样品,每个样品
个样品,每个样品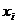 有
有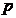 个变量,它们的观测值可以表示为
个变量,它们的观测值可以表示为
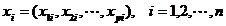
一、样品间的距离
下面介绍在聚类分析中常用的几种定义样品与样品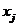 间的距离。
间的距离。
1、Minkowski 距离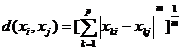
2、绝对值距离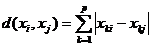
3、欧氏距离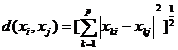
二、变量间的相似系数
相似系数越接近1,说明变量间的关联程度越好。常用的变量间的相似系数有
1、夹角余弦
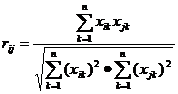
2、相关系数
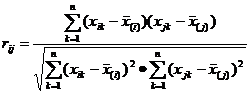
值得注意的是,当指标的测量值相差较大时,直接使用以上各式计算距离或相似系数常使数值较小的变量失去作用,为此需应先对数据进行标准化,然后再用标准化的数据来计算。标准化的具体方法是:
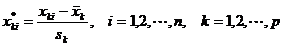
其中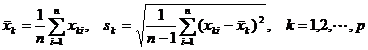
三、类与类之间的距离
用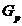 和
和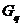 分别代表两个类,它们所包含的样品个数分别记为
分别代表两个类,它们所包含的样品个数分别记为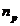 和
和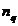 ,类和之间的距离记为
,类和之间的距离记为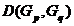 。下面给出三种最常用的定义方法。
。下面给出三种最常用的定义方法。
1、最短距离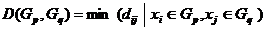
类与类之间的最短距离有如下的递推公式,设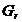 为由和合并所得,则与其它类
为由和合并所得,则与其它类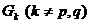 的最短距离为
的最短距离为
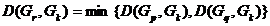
2、最长距离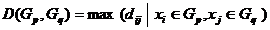
类与类之间的最长距离有如下的递推公式,设为由和合并所得,则与其它类的最长距离为
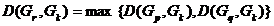
3、类平均距离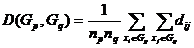
类与类之间的类平均距离有如下的递推公式,设为由和合并所得,则与其它类的类平均距离
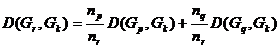 ,其中
,其中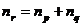 。
。
以上类与类之间的距离,不但适用于Q型聚类,同样也适合于R型聚类,这只要将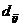 用变量间的相似系数
用变量间的相似系数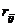 代替就行了。为简单起见以下均记成。
代替就行了。为简单起见以下均记成。
系统聚类法是目前最流行的方法。
有了样品间的距离(或变量间的相似系数)以及类与类之间的距离后,便可进行系统聚类,基本步骤如下:
1、个样品(或个变量)一开始看作类(类),计算两两之间的距离(或相似系数),构成一个对称矩阵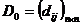 ,此时显然有
,此时显然有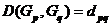 ;
;
2、选择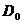 中对角线元素以外的下三角部分中的最小元素(相似系数矩阵则选择对角线元素以外的最大者),设其为,则将和合并为一个新类。在中划去和所对应的两行与两列,并加入由新类与剩下的未聚合的各类之间的距离所组成的一行和一列,得到一个新的矩阵
中对角线元素以外的下三角部分中的最小元素(相似系数矩阵则选择对角线元素以外的最大者),设其为,则将和合并为一个新类。在中划去和所对应的两行与两列,并加入由新类与剩下的未聚合的各类之间的距离所组成的一行和一列,得到一个新的矩阵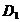 ,它是降低了一阶的对称矩阵;
,它是降低了一阶的对称矩阵;
3、由出发,重复步骤2得到对称矩阵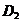 ,依此类推,直到个样品(或个变量)聚为一个大类为止;
,依此类推,直到个样品(或个变量)聚为一个大类为止;
4、在合并过程中记下两类合并时样品(或变量)的编号以及合并两类时的距离(或相似系数)的大小,并绘成聚类图,然后可根据实际问题的背景和要求选定相应的临界水平以确定类的个数。
上面是一个Q型聚类问题,现在用系统聚类法来解决。将每个省份看成一个样品,并以1,2,3,4,5分别表示辽宁、浙江、河南、甘肃、青海5省,计算样品间的欧氏距离,得到如下的距离矩阵
{1} {2} {3} {4} {5}

下面给出采用最短距离法的聚类过程:首先将5个省各看成一类,即令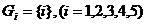 。从可以看出,其中最小的元素是
。从可以看出,其中最小的元素是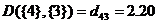 ,故将
,故将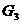 和
和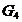 合并成一类
合并成一类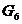 ,然后利用递推公式计算与
,然后利用递推公式计算与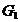 ,
,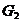 ,
,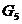 之间的最短距离。
之间的最短距离。
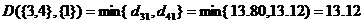
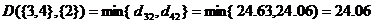
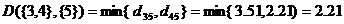
在中划去{3},{4}所对应的行和列,并加上新类{3,4}到其它类距离作为新的一行一列,得到
{3,4} {1} {2} {5}
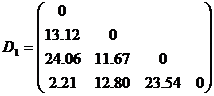
重复上面的步骤,依次可得到相应的距离矩阵如下:
{3,4,5} {1} {2}
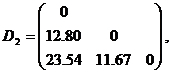
{3,4,5} {1,2}
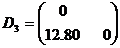
最后将5个省合并为一大类,画出聚类图如下:

 辽宁
辽宁

 11.67
11.67
浙江
12.80
 河南
河南
 2.20
2.20


 甘肃
甘肃
2.21
青海
由此可见,分成三类比较合适,即辽宁和浙江各为一类,河南、甘肃、青海为一类。
若类与类之间的距离用最长距离或类平均距离,也会得到相同的结论。